Hello everyone,
I was thinking about what should be my first blog post about. Then I decided that it would be cool to have some articles about not so common vulnerabilities in web application. Everyone knows about SQL injection or XSS . Instead of trying to describe something what has been described 10000 times already I decided to write about not so common flaws.
First of all what a host header is? This header can usually be found in HTTP request, it’s main purpose is: “The Host request-header field specifies the Internet host and port number of the resource being requested, as obtained from the original URI given by the user or referring resource” RFC2616 says.
Where is the risk?
The risk comes from simple truth – many sites use value provided in this field and use it later without proper input validation. In many cases this might not have any significant impact but there are other places in the application where accepting arbitrary host header can have pretty bad consequences.
How do I test for this?
Easily. You either purchase that awesome tool BurpSuite Pro and install extension called “Active Scan++” or you can do it old school way with NetCat. For NC testing you can just use this:
NC -vv goodguy.com 80
After connection is established you just write:
GET / HTTP/1.1
Host: goodguy.com
Normal response should be received because this is all fine. However connect with netcat and submit following:
GET / HTTP/1.1
Host: badguy.com
Was the response same as in previous example? If yes you might just found arbitrary host header vulnerability. Why is this bad? Well because application obviously returned content although we specified invalid/incorrect Host header.
Ok, but how can I exploit this?
It really depends on the application logic. If the application does not use this value then there is no risk. Thankfully there is one particular place where this issue can be deadly – password reset functionality. It happens a lot when you are resetting forgotten password, application creates link dynamically and use host header provided in request. This happens very often in case of cms developed for masses. It is convenient for developers just to use this header because they don’t have to hardcode anything. But they forget that everything coming from user can be changed/spoofed/edit so it cannot be trusted (remember this very carefully, it is golden rule in IT security world)!
Some examples:
- https://www.exploit-db.com/exploits/8196/ – WP failed to sanitize host header and BOOM – XSS
- https://packetstormsecurity.com/files/112249/Joomla-2.5.3-Host-Header-Cross-Site-Scripting.html – the same but affecting Joomla
Yes, these examples show how to use Host header attack to do XSS. I promised you some password-reset-link-poisoning so here it comes 🙂
Recently we (by we I mean my pentesting company https://captes.cz) did a pentest for one of our customers. The application had pretty limited functionality so after quick recon we weren’t really hoping for any high/critical findings. But then we stumbled upon password reset functionality. We quickly validated host header poisoning is possible and aimed for exploitation. It was the case where the application took host value from request header and used it a bit later when putting together password reset link. How did the exploitation go? We just requested page ourcustomer.com/resetpassword.php, there we filled in our email address and clicked on “Password reset button”. Our BurpPro was listening so we captured the request which looked like this:
GET /auth/reset_password?email=pentest@ourcutomer.com
Host: ourcustomer.com
Cookie: ...
Then we checked mailbox provided by our client – we indeed received password reset email which contained typical sentence:
“Here is your password reset LINK” – LINK was hyperlink pointing to ourcutomer.com/auth/reset_password/32493jrfie78434hud20d230942u3d
In this case all is fine and non-malicious at all. If you click this link you will land at our customer web page and you will be prompted for new password. After verifying desired functionality we finally tried attacking the application. We sent request which was very similar to original one, expect one difference:
GET /auth/reset_password?email=pentest@ourcutomer.com
Host: captes.cz
Cookie: ...
Yes you guessed it! We used our own host header. Do you have any idea what happen next? Again we received password reset email, but this time if you looked at the LINK it was pointing to:
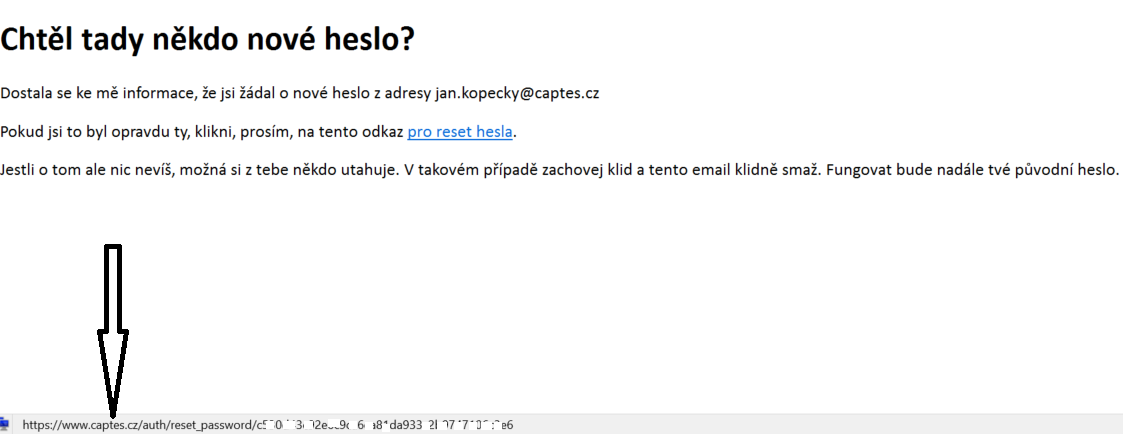
Sorry the email is in Czech but is says: “Anyone asked for new password?” then some usual phrases and finally link pointing to https://captes.cz/auth/reset_password/2398n4c324mx032948nv2309n4x20m
This is awesome, isn’t it? We can send email to arbitrary user of the application and make sure his password reset link will be poisoned. As soon as victim clicks the link his token appears in our logs – that’s it – game over for victim, we can hijack the account.
Here are some thoughts to increase a chances of this attack being successful:
- A user is most probably not gonna click the link because he did not ask for password reset. Well there comes social engineering to rescue! You can be creative and come up with your own reason why he should click. Our first email to victim had following idea: “Dear client, unfortunately we have to inform you our systems have been breached and there is high chance password leaked as well. To deny attacker accessing your webpage with leaked password you have to reset your current password. Reset link will be sent to your email address in a few minutes”. Right after you send this email you can send the poisoned one. Of course better your social engineering email is higher are chances user clicks the link.
- After user clicks password reset link and lands at your web page make sure you just don’t leave him there because he might get suspicious like “dude what is going on? I clicked on password reset link and ended up on completely different domain”. This would screw up your attack for sure. As soon as you have the access token just redirect user back where he should have landed originally.
So far we have covered two cases – XSS and password reset link poisoning. There is one more options I want to cover here. It it cache poisoning. To understand this issue it is important to understand how many devices/software look at your request along it’s way from browser to server (now I’m only speaking about layer 7). When your request is making it’s way across network there usually are proxies, WAFs, load balancers and of course the server itself. The problem here is inconsistency. Let’s take example from past. There is one caching solution called Varnish, when Varnish receives HTTP request which looks like this:
GET /index.html HTTP/1.1
Host: attacker.com
Host: goodguy.com
guess which header it is gonna take as more significant? It is first header. What happens when this request arrives to ngix server? Well ngix prefers the last host header… you see where this is going? Imagine your company use Varnish as caching solution and you have colleague who likes pranks. What happens if your funny friend send the following request:
nc -nvv attacker.com
GET /index.html HTTP/1.1
Host: myfavouritewebpage.com
Host: attacker.com
Correct – this request leaves your company network and Varnish will cache the response as it was for myfavouritewebpage.com. Ngix on the other hand sees valid attacker.com and will return it’s context. This means your company’s Varnish cache will be poisoned in such a way that when someone writes myfavouritewebpae.com to his browser content of attacker.com is returned.
That is pretty much all folks. Just one more thing, references:
http://seclists.org/fulldisclosure/2008/Jun/169 – this is (at least to my knowledge) very first reported abuse of host header
http://www.skeletonscribe.net/2013/05/practical-http-host-header-attacks.html – very informative article about this topic